
Microservices have taken our industry by storm. Teams around the world have ditched their clumsy monoliths in favor of chasing the dream of loosely coupled, manageable, and independently deployable microservices. Unfortunately, many of them ended up worse off than they were before - in the realm of distributed monoliths. Why?
“If I had an hour to solve a problem I’d spend 55 minutes thinking about the problem and 5 minutes thinking about solutions” - Albert Einstein
In my opinion, this quote is the key to solving most of the issues we have when designing microservices-based systems. We rush into solutions without ensuring we know what exactly a microservice is. In this post, I’d like to take a stab at answering this question.
Before we delve into microservices, let’s start from the beginning and talk about the term “service”.
What is a Service?
According to the [OASIS definition], a service is a mechanism that enables access to one or more capabilities. In our case, these capabilities might be executing commands, querying, or raising events. All of them make up a service’s public interface.
Here is an example of a backlog management service:
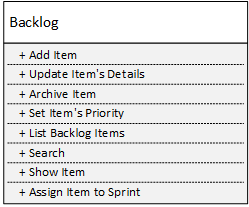
Now let’s see what makes a service a microservice.
What is a Microservice?
If a service is a mechanism that enables access to one or more publicly executable operations, then a microservice is a service with a “micro” public interface. It provides as few public operations as possible - literally, a “micro”-service.
The reason for this heuristic is autonomy. That’s what we are looking for when we implement this architectural style – autonomous services. However, a service cannot be fully autonomous and independent from its environment. Such a service wouldn’t have any public interfaces at all, and consequently wouldn’t be able to receive or expose any data. It would be fully autonomous, but useless. However, we can increase autonomy by limiting the service’s and its clients’ reasons for change: the smaller the public interface, the less coupled the service is to its environment. Thus, it is more autonomous.
Designing services in such a way that minimizes their public interfaces sounds simple, right? It’s not.
From Microservices to Systems
A naive approach would be for each microservice to expose only one public operation. You can’t have a smaller service than that, right?
In the case of our backlog management service, a “naive” microservice would look like this:
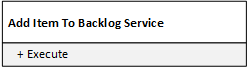
This decomposition would make sense if we were in the business of delivering microservices. But we aren’t. Independent microservices do not provide any value for our clients. They only do this when they are composed into working systems – and that’s what we’re paid for.
Let’s see what would happen if we were to compose a backlog management system out of the “naive” set of microservices.
Since we want well-behaved microservices, each of them would have its own database:

And since all those databases manipulate the same set of business entities, the data should be replicated and synchronized across many of them. For that purpose, the services will have to expose their data in some way – let’s say, by means of raising events:

And that’s how the data would flow between them (Warning! Graphic content) :
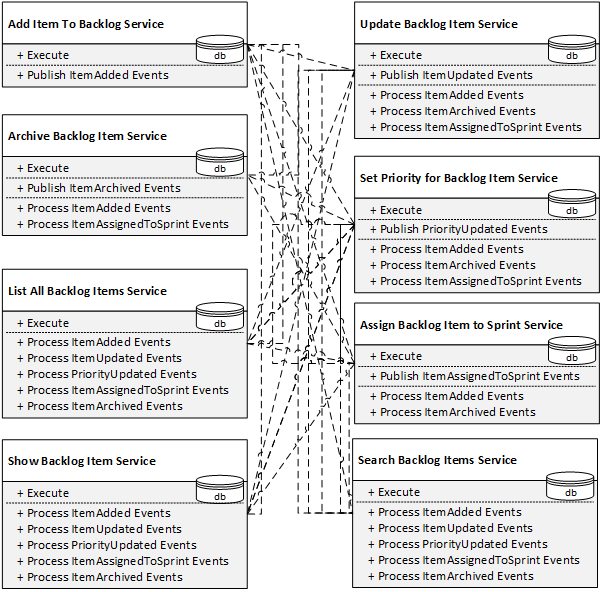
We started with one public operation per service, but to implement the system’s Use-Cases we ended up with an average of 4.75 methods per service. Moreover, the system’s total number of public operations went from 8 to 38! And to make matters even worse, some of them would even have to participate in distributed transactions. So much for autonomous, independently deployable, and manageable microservices. Blurg!
Let’s see what happened here. We went way too far with decomposing the system into services. I don’t even call them microservices! To support the system’s use cases, the public interfaces of those services grew out of control, and the integrations between them skyrocketed. This accidental interface complexity led us straight into the dead-end called a Distributed Monolith.
Therefore…
What Are Microservices?
The microservices architecture is the decomposition of a system into a set of services, such that all services will have minimal public interfaces.
The threshold upon which the system can be decomposed is defined by the use cases of the system that the microservices are a part of.
This definition supports the known fact that each microservice should have its own database. That’s because in other the case, one of the services would have to expose its database as its public interface. And this huge public interface would make it a macro-service.
P.S.
“Bounded Contexts, Microservices, and Everything in Between”: the talk I gave at the DDDX 2018 conference, where I spoke on this topic - what exactly Microservices are, strategies for decomposing systems into services, and heuristics for finding Microservices’ boundaries.